
Firecrawl and Bright Data can both get web data for you, but they are not really trying to do the same job. One feels like a focused tool for AI builders who want clean output fast, while the other feels like a much bigger data infrastructure platform with more moving parts.
That difference matters because the wrong pick gets expensive fast. If you just want to feed AI agents, RAG pipelines, or internal automations with usable web content, you probably do not want to pay for complexity you will never use.
This review is here to help you decide whether Firecrawl is the smarter buy, whether Bright Data is worth the extra weight, or whether you should wait and pick based on your real workload instead of marketing claims.
Article outline
- Quick verdict
- What you will see in the rest of this review
- What you get when you start testing
- The good stuff
- Pricing and value
- Alternatives worth comparing
- My honest verdict
- FAQ
Quick verdict
If your main goal is getting AI-ready web data without building a mini scraping stack around it, Firecrawl looks like the better fit. It gives you one API, markdown and structured output by default, a free entry point, and pricing that is easier to understand before you accidentally run up a bill.
Bright Data is still a serious option, but it makes more sense when you need a broader web-data machine. If you care about massive proxy infrastructure, lots of specialized scrapers, compliance-heavy enterprise buying, or multiple ways to collect data across products, it can justify the extra complexity.
Explore FirecrawlThat does not mean Firecrawl wins for everyone. If you are buying for a larger data team, need access across many collection methods, or you already think in proxies, zones, crawler jobs, and large-scale record delivery, Bright Data may still be the more capable platform.
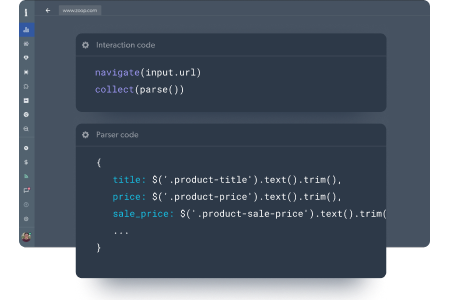
Image source: Bright Data Web Scraper IDE
What you will see in the rest of this review
Next, I am going to look at what each tool gives you when you first start testing it. That is usually the fastest way to tell whether you are buying something practical or something that will sit in your backlog while you figure out setup.
After that, I will break down what Firecrawl does better, where Bright Data still has an edge, and how pricing changes the decision. That matters because a tool can look cheap at the start and still become annoying once your usage pattern gets real.
The last section will compare alternatives directly and give you a plain-English verdict. You should leave with one of three answers: start Firecrawl now, wait until your project is more mature, or go with a broader platform because your needs are already bigger than a focused AI scraping tool.
What to keep in mind before you move on
Firecrawl gives you a cleaner low-friction test: 500 free credits, no card required, and standard scrape or crawl actions usually costing 1 credit per page. That makes it easier to judge value quickly because you can estimate what normal usage might look like before you commit.
Bright Data also offers free trials on the products I checked, and some of its scraping products start with pay-as-you-go pricing instead of a required monthly subscription. The catch is that Bright Data spreads capability across multiple products, which is powerful, but it also makes the first buying decision less obvious if you are still figuring out your actual use case.
That is the real split in this Firecrawl vs Bright Data decision. Firecrawl feels easier to buy when you already know you want AI-ready extraction, while Bright Data feels easier to justify when you need a bigger web-data platform and are fine paying for that extra surface area.
What you get when you start testing
Firecrawl makes the first decision easy. The current free plan gives you 500 one-time credits, no card requirement, 2 concurrent requests, and a clean way to see whether scrape, crawl, map, and search are enough for your workflow before you spend anything.
Bright Data can absolutely do serious work, but the starting point is less clean. Its pricing is split across products, and the entry plan most people land on first is usually a product-specific trial or pay-as-you-go setup rather than one obvious “just start here” path.
That matters more than it sounds. If you are comparing Firecrawl vs Bright Data because you want usable web data for agents, RAG, internal tools, or automations, Firecrawl lets you answer that question faster and with less guesswork.
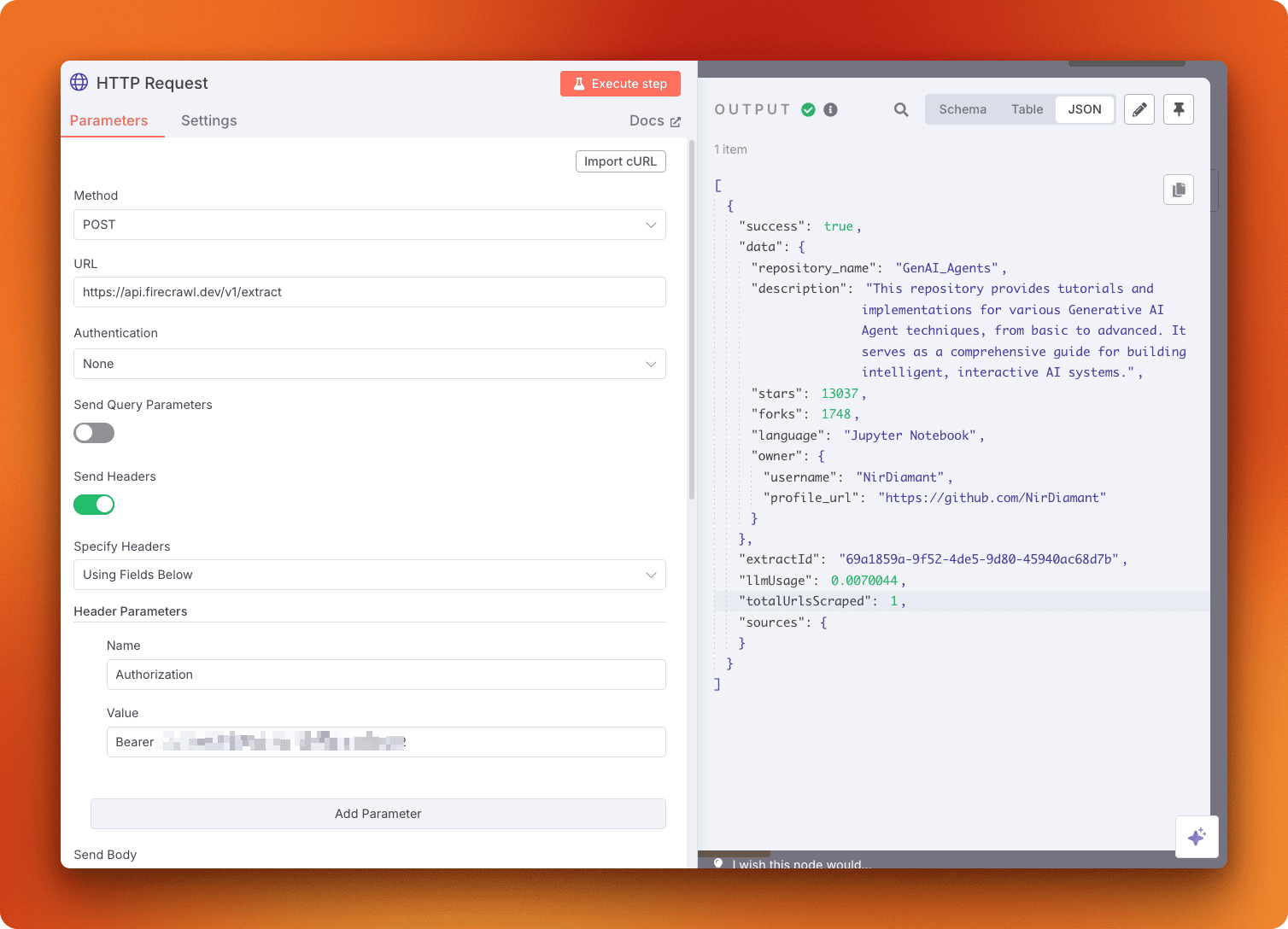
Image source: Firecrawl blog
Firecrawl also feels friendlier when you want proof fast. A simple scrape usually costs 1 credit per page, and the same pricing model extends across crawl and map, so you can tell pretty quickly whether the tool is cheap enough for your actual usage instead of hoping the bill works out later.
Bright Data is better when your needs are already bigger than a simple scrape-and-return workflow. Its broader stack makes sense for teams that need multiple scraping products, heavy proxy infrastructure, or wider collection options across more specialized jobs.
Most people reading this are not there yet. They want web content cleaned up, structured, and ready to use without assembling a full scraping operation first.
Start Firecrawl freeThe good stuff
Firecrawl earns its price by cutting out the messy middle. You are not just pulling raw HTML and hoping your parser survives the next layout change.
The current product pitch is still the right one: clean markdown, structured JSON, screenshots, and web data workflows built for AI use cases. That sounds simple, but it is the difference between getting useful content back and spending another day cleaning garbage output.
Bright Data has moved closer to this than a lot of old comparisons suggest. Its Crawl API now supports Markdown, HTML, plain text, and structured schemas, so this is not a case where Bright Data is stuck in a purely old-school scraping world.
Firecrawl still feels better focused. The whole product is sold around turning websites into LLM-ready data, not around making you choose from a wider catalog of products before you even know which billing model fits your job.
That focus helps with setup too. Firecrawl’s docs and product pages keep pointing you toward one practical outcome: search, scrape, crawl, or interact with the web, then plug that output into the thing you are building.
Bright Data has more surface area. That is great when you need it, but it is also why smaller teams often end up paying for capability they barely touch.
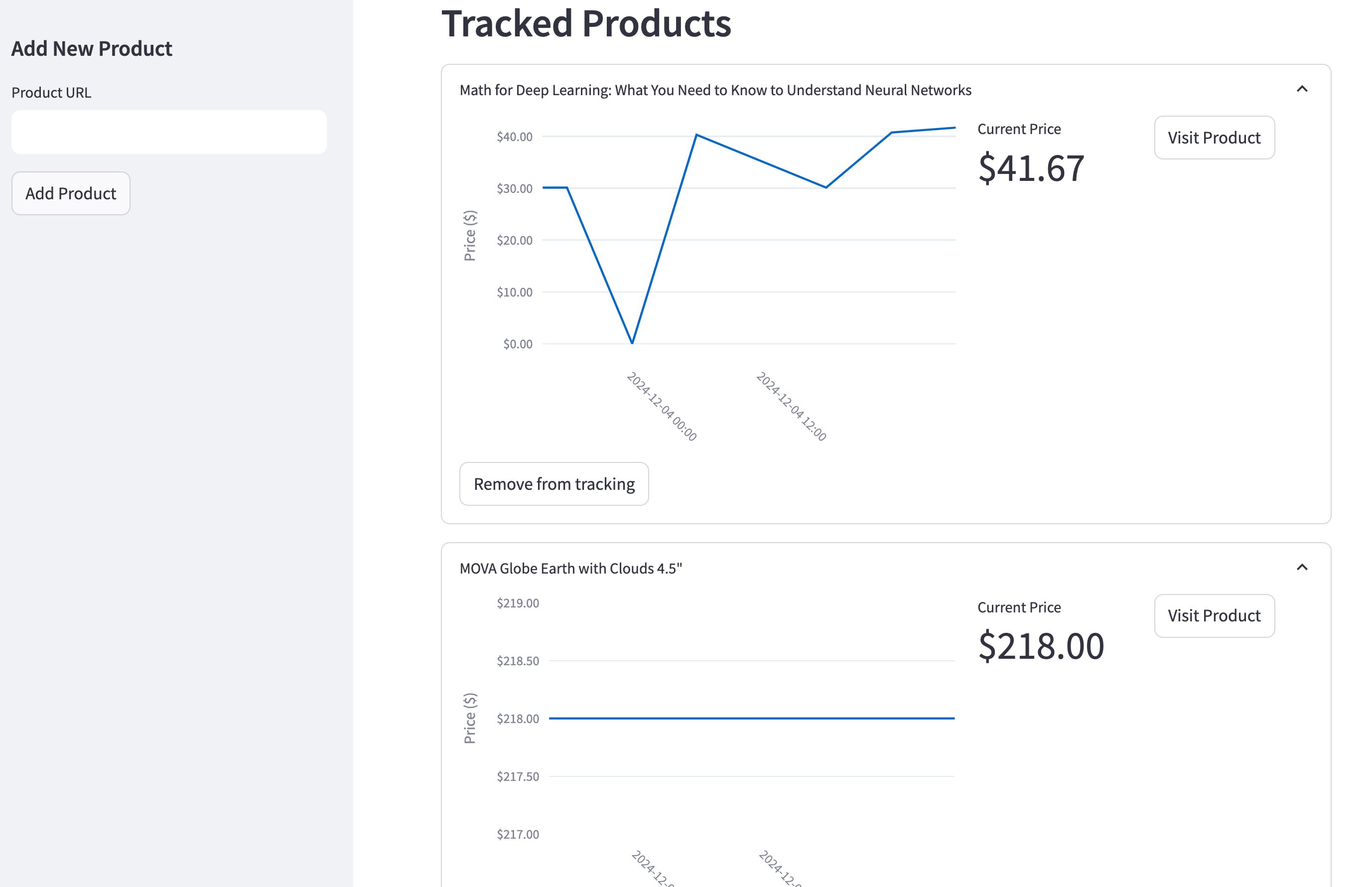
Image source: Firecrawl blog
The other thing Firecrawl does well is make the payoff easy to understand. You can use it for price tracking, site monitoring, data extraction, internal research tools, and agent workflows without needing five separate services just to get a usable result.
That is why it feels better than doing this manually. Manual scraping is cheap only if you ignore the hours you burn on selectors, retries, blocked pages, broken jobs, and cleanup after the output comes back ugly.
Firecrawl is not perfect. Credits do not roll over on normal plans, advanced features can cost more than a plain scrape, and high-volume teams may outgrow the simpler plans faster than they expect.
Bright Data still wins when compliance-heavy scale, broader infrastructure, or specialized scraping products are the real requirement. Firecrawl wins when speed, clarity, and AI-friendly output are the priority.
Pricing and value
Firecrawl looks stronger on value if you want to test, build, and scale inside one predictable credit model. The free plan is genuinely useful, the first paid plan is approachable, and the jump to bigger plans is easy to read before you buy.
Bright Data can still be worth it, but the value case depends on buying the right Bright Data product. That is a better fit for experienced teams than for someone who mainly wants a cleaner path from URL to usable data.
See Firecrawl pricingThat table also answers the biggest objection most buyers have: overkill. Firecrawl is easier to justify when you want one tool that gets web data into a usable format fast, while Bright Data is easier to justify when you know you need the bigger machine.
You should also be honest about adjacent tools. If your real goal is turning knowledge into a customer-facing site assistant, Chatbase is the cleaner buy for the chat layer, while Firecrawl is the stronger buy for getting fresh site content into shape first.
If the real bottleneck is leads, follow-up, CRM, funnels, and automation after the data is captured, GoHighLevel is the broader all-in-one. It is not a Bright Data replacement, but it can be the smarter spend if scraping is only a small piece of the business problem.
Why buying now can make sense
Firecrawl is worth buying now if you already have a use case in front of you. A live agent, a monitoring workflow, a research tool, or a content pipeline is enough reason, because the cost of waiting is usually more manual cleanup and more delay.
That does not mean everyone should jump in today. If you are still vague on what you want to scrape, how often you need it, or what the output needs to look like, the free plan is the right move and a paid plan can wait.
For the right buyer, this is not hard to justify. You only need one working workflow to see why paying for clean output beats spending hours fixing brittle scraping logic by hand.
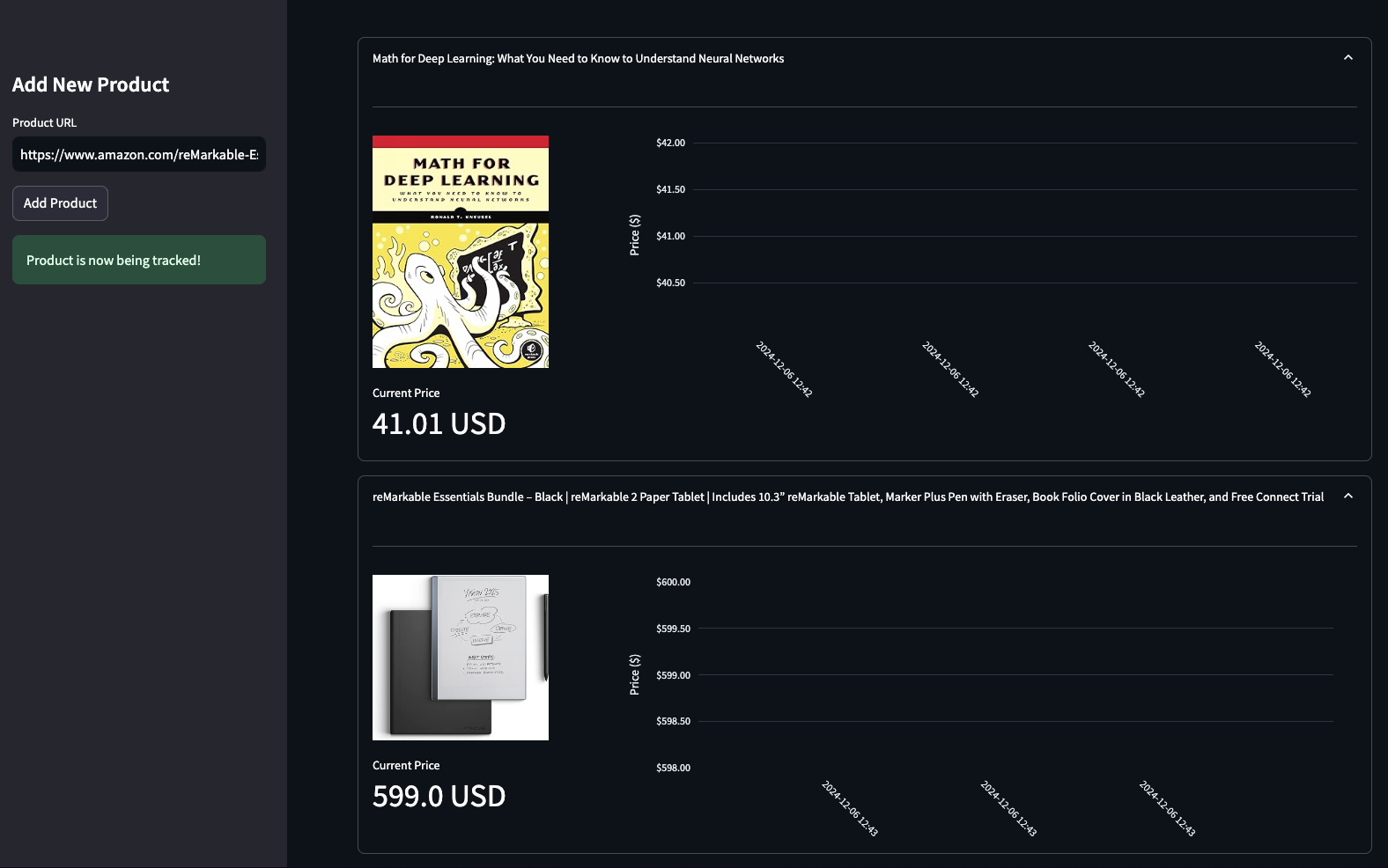
Image source: Firecrawl blog
My take is simple. Firecrawl is the better choice for most readers comparing Firecrawl vs Bright Data because it gets you to a useful result faster, with less buying friction, and with pricing that makes sense before your project gets complicated.
Bright Data is still the stronger pick for bigger, broader, heavier-duty operations. Firecrawl is the smarter pick for the person who wants to build now instead of shopping for infrastructure all week.
Alternatives worth comparing
Firecrawl is not the only good option here. The smart move is picking the tool that matches the size of your job, not the one with the longest feature page.
Firecrawl vs Bright Data is the big decision if you want a hosted product and you care about AI-ready output. After that, Apify and Crawl4AI become relevant if you want either a more flexible marketplace-style setup or a cheaper self-hosted path.
Check the official Firecrawl trialPick Firecrawl if you want the cleanest path from URL to AI-ready output. Pick Crawl4AI if budget matters more than convenience, and pick Bright Data if your real need is a bigger web-data machine with more infrastructure behind it.
A broader all-in-one alternative only makes sense if scraping is not your main bottleneck anymore. If you mainly need CRM, funnels, follow-up, and business automation after the data work is done, GoHighLevel is the better place to spend money than forcing a scraping tool to solve a sales-ops problem.
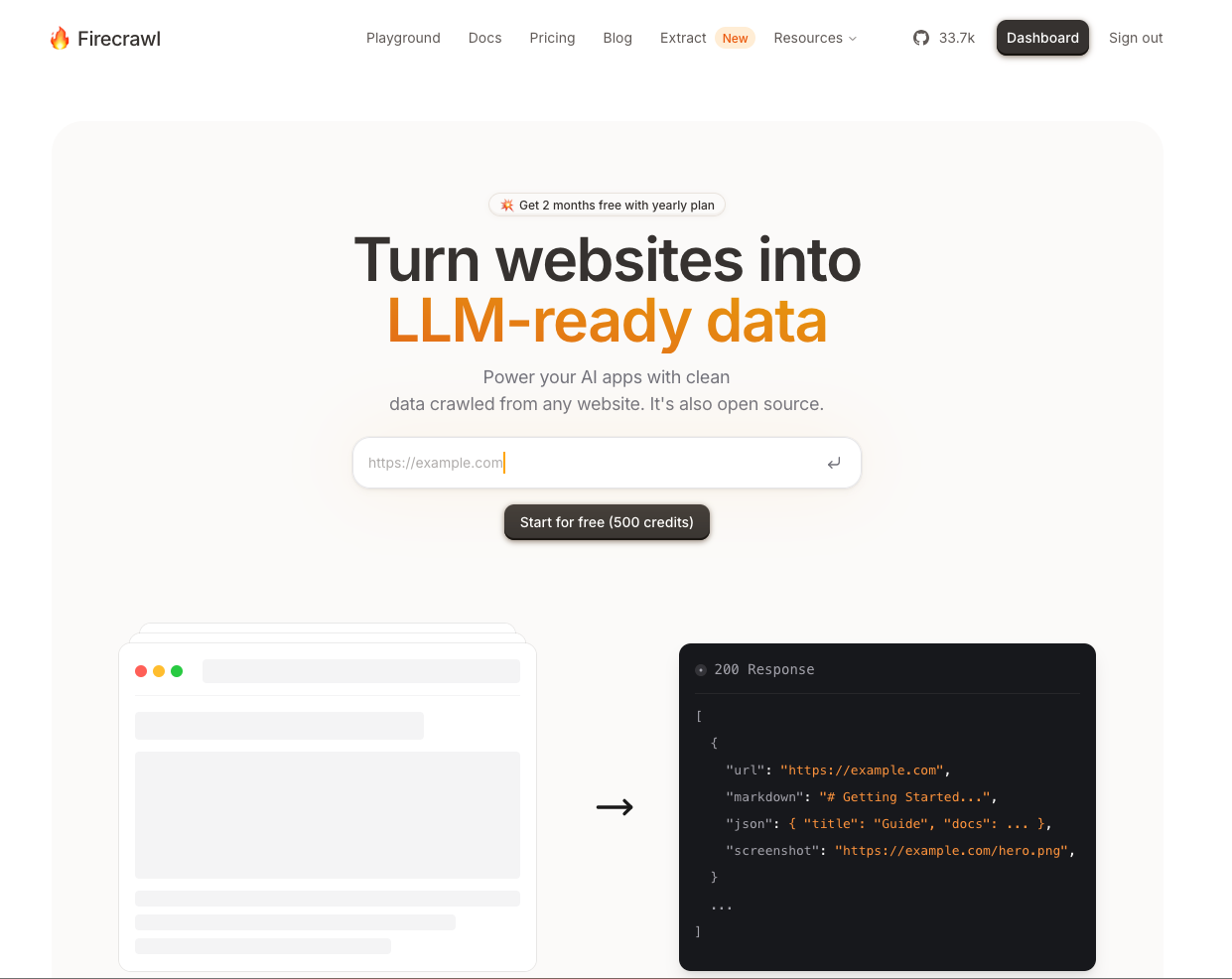
Image source: Firecrawl
My honest verdict
Firecrawl is the better buy for most people comparing Firecrawl vs Bright Data. It gets to the point faster, costs less to understand, and feels built for the kind of AI workflows that most buyers actually want to launch right now.
Bright Data is still the stronger enterprise pick when scale, proxy depth, specialized scrapers, and broader infrastructure matter more than simplicity. That does not make it the better choice for the average buyer, because average buyers usually need faster progress more than a larger stack.
Firecrawl is not for everyone. If you are extremely price-sensitive and happy to self-host, Crawl4AI can be smarter, and if you want a broader scraping marketplace with more plug-and-play actors, Apify deserves a serious look.
For the right buyer, Firecrawl is absolutely worth trying now. If you already have a use case in front of you, waiting usually just means more manual cleanup, more duct-taped scripts, and more time lost before you get a working workflow.
I would skip the paid plan for now only if your project is still fuzzy. If you do not know what you need to scrape, how often you need it, or what format the output needs to be in, start free first and let the real usage tell you whether the paid plan is justified.
Image source: Firecrawl
FAQ
Should beginners use Firecrawl or Bright Data?
Beginners will usually have an easier time with Firecrawl. Bright Data makes more sense once you already know you need a wider set of data products and you are comfortable buying into a more complex setup.
Is Firecrawl cheaper than Bright Data?
Firecrawl usually feels cheaper to start because the free plan is simple and the paid plans are easy to read. Bright Data can be cost-effective at scale, but it is harder to estimate quickly because pricing depends on the specific product and workload.
Can Firecrawl replace Bright Data completely?
Not for every team. Firecrawl can replace a lot of lighter AI-focused web extraction work, but Bright Data still has a stronger case when you need deeper infrastructure, broader scraping options, or heavier enterprise workflows.
What if I want the cheapest option possible?
Crawl4AI is the one to look at if software cost matters most and you are comfortable doing more of the work yourself. Firecrawl is the better choice if you want a managed tool that saves time fast.
Is Firecrawl overkill for small projects?
Not really, because the free tier lets you test without much friction. It only becomes overkill when your project is still too undefined to tell whether clean markdown, structured extraction, or crawling will actually matter to you.
Image source: Firecrawl
Should you start with Firecrawl?
Start now if you already have a workflow waiting for clean web data. That is where Firecrawl earns its price fast and feels easier to justify than building and maintaining the same thing by hand.
Wait if your use case is still vague. Skip it only if you know you need a bigger enterprise stack like Bright Data or a cheaper self-hosted route like Crawl4AI.
Get started with Firecrawl